
第1章 機械学習の概要とライフサイエンス研究への応用
清水秀幸
(東京医科歯科大学M&D データ科学センターAI システム医科学分野)
1.1AlphaFold2の衝撃
2021年7月,DeepMind社が開発した人工知能(AI)であるAlphaFold2がタンパク質のアミノ酸配列から立体構造を非常に正確に予測したこと1)は,間違いなく生命科学界を大きく変える一歩になるであろう.タンパク質のアミノ酸配列がその立体構造を決定し,それがシグナル伝達や化学反応触媒といったタンパク質の機能に影響することはよく知られている2).1950年代にJohn Kendrewがミオグロビンの立体構造を決定し,またX線結晶構造解析法がタンパク質構造決定のための標準的な実験手法として確立されたが,実験的構造解析には高いコストと技術的な限界があることから,コンピューター予測にも多大な研究者が関わってきた.
1994年に開始されたCASP(Critical Assessment of protein Structure Prediction)は,構造が実験的に解かれたがまだ公開されていないデータに対し,挑戦者たちがそのアミノ酸配列のみから構造を推定し,後に「正解」との比較によりコンピューター手法の客観的な比較検証を行う国際大会である.当初は物理学的なエネルギーを見積もるアプローチ3)や知識ベースの統計的アプローチが成績上位の中心であったが,近年は機械学習や深層学習を活用した手法も登場しており,大会のたびに大きな進展が見られるようになっていた.13回目の国際大会であるCASP13に初参加したGoogleのDeepMindグループが実装したAlphaFoldは2位の手法と接戦ながらも初優勝し,その詳細は2020年のNature誌に報告されている4).CASP13で優勝したのにもかかわらず,2年後のCASP14に向けて一からすべて作り直したのがAlphaFold2であり,2位の手法に大差をつけて優勝して大きな話題となった1).AlphaFold2と,いわばAlphaFold1はまったく異なる仕組みであり,単なるバージョンアップではないことに注意されたい.
タンパク質の進化の概念を取り入れたマルチプルシークエンスアライメント(MSA)5)は多方面にわたるタンパク質情報科学研究で使われており,これによりタンパク質の進化情報を応用した表現を学習できるようになっていた.さらにタンパク質の不変性と対称性に着目した新しいアテンション(注意)機構やグラフベースの表現,モデルのリサイクル戦略など,モデル設計の革新にもAlphaFold2の大躍進の秘訣がある.AlphaFold2論文には,情報系の論文10報分に相当すると言っても過言ではない新工夫が随所に盛り込まれている.
AlphaFold2は,AIに関する十分なスキルがある一部の研究者だけが使えるものではもはやない.簡略版であればGoogle Colaboratoryで動かせる注1)し,日本語の解説動画もTogoTVで公開されている注2).さらに,DeepMind社は欧州分子生物学研究所(EMBL)と提携し,AlphaFold2で予測したタンパク質構造をオープンにし世界中の誰でもアクセスできるようにしている注3).このデータベースは,公開された時点ですでにヒトタンパク質の98.5%をカバーしており,少なくともその36%のアミノ酸残基が高い信頼度で予測されていた.さらに驚くべきことに,本原稿を執筆中の2022年7月下旬,UniProtに登録されているほとんどすべてのアミノ酸配列(さまざまな生物種,2億以上のアミノ酸配列)に対する構造予測を行い,それらのデータも無償で公開するとDeepMindが発表しGoogle Cloud Platform経由でバルクダウンロード可能になっている注4).
AIの進歩はとどまるところを知らず,少し前まではまったく不可能であったことも数年後には常識になっていることは多々ある.幸いなことに,AI界隈は非常にオープンなコミュニティでありチュートリアルも多数あるし,AIそのものを研究するのではなくAIを自分の研究に取り入れるだけであれば比較的簡単に扱える優れたパッケージ・ライブラリがたくさん出ている.本書でバイオメディカル領域のAIに関する入門的な知識を身につければ,そういったインターネット上の有益なリソースを独学で読み解いていけるようになる.ぜひAIをご自身の研究の強い相棒にしていただきたい.
1.2機械学習速習
それではまず最初に生命科学に大変革を起こし始めた機械学習とは何者なのか,その概略を説明しよう.
1.2.1機械学習とは何か?
AIは人間の知能を模倣するためにコンピューターを応用した研究分野であり,古くは実は第二次世界大戦が終結する前の1943年頃から概念としては存在していた.生物学的な脳のニューロンによる情報処理のモデルとして「人工ニューロン」が初めて提案されたのはこの頃だ7).詳細は割愛するが,AIはその後何度か隆盛と衰退を繰り返しつつも,遺伝的アルゴリズムや焼きなまし法といった今日でも使われているさまざまな手法が開発されてきた.
AIのさまざまなアプローチがある中で,主に統計科学と密接な関係を保ちながら発達してきたのが機械学習(machine learning,ML)である.機械学習は,データから統計理論をもとに学習し,学習したことを利用してまだ見ぬデータに対して判断を下す分析手法である.何やら難しそうだが,全然そんなことはない.例えば読者はすでに線形回帰(linear regression)を使ったことがあろう.例えば検量線の作成のように,いくつかの実験データをプロットし,それらの点のそばを通る最も良さそうな直線を引いて,対応関係を探るというおなじみの作業だ.直線の「学習」には最小二乗法を使うことが多いが,これは統計学的には
機械学習を行ううえでは,特徴量(feature),すなわちデータのどのような点を使えばよいのかということを,その道のプロが手動で指定する必要がある.特徴量を指定すれば後は自動で学習してくれるのだが,最初の特徴量を指定するところは手動なのだ.複数の変数を組み合わせた新たな変数を使ったほうが望ましいこともあるが,そういう調整はしばしば職人芸的であり,解きたい問題に対する専門的な知見(ドメイン知識)が要求される.特徴量工学(feature engineering)とも呼ばれるこのような処理こそが機械学習の最終的なパフォーマンスに大きな影響を与える要素であり,非常に多くの労力を割いて取り組む必要があった.
ところが,機械学習で必要とされた特徴量工学をも自動化する方法が近年非常に注目を集めている.それこそが深層学習(deep learning,DL)であり,データのみから学習させることができる方法である.全自動である代償として,深層学習以外の機械学習の手法と比べてより多くのデータが必要になるのだが,近年はその代償を克服するためのさまざまなアプローチがある.とりあえず今のところはここはスキップして先に進もう.
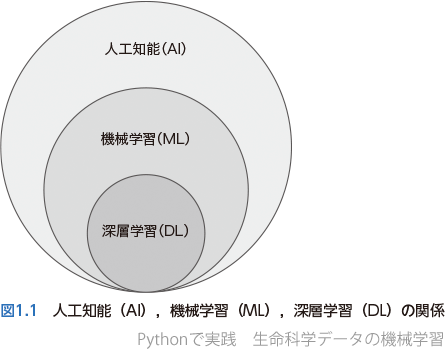
この項で抑えておいてほしいことはたった1つであり,それは人工知能(AI),機械学習(ML),深層学習(DL)の関係だ.これらの用語は領域外の方にはしばしばまったく同じものだと勘違いされているが,実際にはそうではない.図1.1に示す通り,AIの中にMLがあり,その中にDLがあるのだ.
1.2.2機械学習が行うこと
コンピューターは数値しか理解できないので,機械学習を理解するうえでは最低限の数学も必要だ.ただあくまでAIを使用するという立場であれば,目安として高校数学の内容プラス大学1年レベルの数学,特に線形代数の知識のみで事足りる.
高校数学で習ったベクトル(vector)を覚えているだろうか? いくつかの数値をひとまとめにして,文字の上に矢印を付けて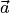 のように表したあのベクトルだ.そのベクトルの延長にある行列(matrix)も思い出したことだろう.ベクトルや行列に関する数学を,大学では線形代数(linear algebra)と言う.機械学習がやっていることは,この線形代数の応用なのだ.機械学習コミュニティでは,ベクトルを意味するときにはアルファベット小文字を太文字にして例えばaのように表し,行列を表現するときにはアルファベット大文字を太文字にして例えばAのように表すので,しばしこの慣習にお付き合いいただきたい.
のように表したあのベクトルだ.そのベクトルの延長にある行列(matrix)も思い出したことだろう.ベクトルや行列に関する数学を,大学では線形代数(linear algebra)と言う.機械学習がやっていることは,この線形代数の応用なのだ.機械学習コミュニティでは,ベクトルを意味するときにはアルファベット小文字を太文字にして例えばaのように表し,行列を表現するときにはアルファベット大文字を太文字にして例えばAのように表すので,しばしこの慣習にお付き合いいただきたい.
xとyを2つのベクトルとする.機械学習の問題の多くは,次のような数学的関数を作ることが目的である.
y = 𝑓 (x)(1)
いきなり数式が出てきたと思ったら,きわめてシンプルでびっくりした読者も少なくないだろう.xに年齢・性別・喫煙歴を,yに肺がんになる確率(1種類の値しかなくても立派なベクトルである)を用意して学習させれば,関数 𝑓 は新たな患者さんがやってきたときにどの程度の肺がんリスクがあるかを推定する有用なツールになる.もちろん肺がんのリスクが高い人はこまめに検診するなど医療介入もできるだろう.冒頭のAlphaFold2がやっているのは,xをアミノ酸配列(を数値ベクトルにしたもの),yをタンパク質の立体構造(3次元座標など)にしただけであり,その間にある関数 𝑓 を機械学習で求めている.さらにベクトルxを細胞の画像データ,yを細胞の位置情報リストにして 𝑓 を求めれば,画像から自動的にすべての細胞を検出してくれるシステムが出来上がるのだが,このように画像を数値ベクトルに変換するのも問題なく行える.画像はRed, Green, Blueの3つのチャンネルを組み合わせて作られているのだが,この3チャンネルに分解し,それぞれのチャンネルで「どれくらい赤(or 緑 or 青)か」ということを例えば0~255の256段階で数値にすれば,1枚の画像を数値がたくさん書かれた3枚のフィルターに,そしてそれを(最もシンプルには)全部つなげることで1つのベクトルxに変換できるのだ.画像解析の実際は第6章で詳しく学んでいただく.
繰り返しになるが,機械学習の本質は(1)における関数 𝑓 をデータから決めることである.もちろんxとyの間の対応関係,つまり 𝑓 は非常に複雑になることもある.関数(あるいはモデル)𝑓 が複雑であればあるほど,自由度の高いモデル,別の言葉で言えば柔軟性が高いモデルになる.そして関数 𝑓 として,いわばどのような「形」を仮定するかによって,線形回帰になったり,サポートベクトルマシンになったり,ランダムフォレストになったり,ニューラルネットワーク・深層学習になったりする.逆に言えば機械学習のさまざまな手法の違いは,単に関数 𝑓 の設定法の違いにすぎない.本書の第4章で使い方を詳しく学ぶ機械学習用のライブラリであるscikit-learnは,ごく代表的な手法についてどのように使い分けるといいかチートシートを公開している注5)ので図1.2に示す.
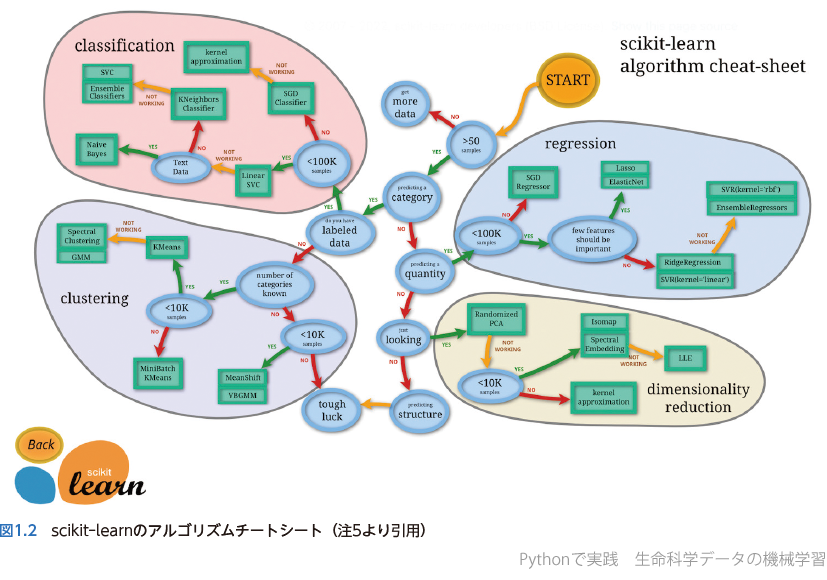
緑枠で囲まれているのが機械学習の手法の名前,いわば関数 𝑓 の設定方法である.本書ではここに書かれていないやや発展的な手法も含めて随時紹介していくので心待ちにされたい.
1.2.3データの「学習」を紐解く
関数 𝑓 (x)が機械学習における「モデル」であることは前述の通りであり,また入力xにどのようなものを使えばいいのか,というところは特徴量工学で述べた通り研究者自らが設定する必要がある.ここではどのようにしてモデルのパラメータを「学習」するのかについて述べていく.
例えば入力x = (𝑥1, 𝑥2)𝑇 を2次元ベクトル,関数 𝑓 として線形回帰 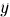 = 𝑤1𝑥1 + 𝑤2𝑥2 + 𝑏 というモデルを考えてみよう(𝑤1, 𝑤2, 𝑏 はそれぞれ実数の定数).
= 𝑤1𝑥1 + 𝑤2𝑥2 + 𝑏 というモデルを考えてみよう(𝑤1, 𝑤2, 𝑏 はそれぞれ実数の定数).
高校でのベクトルは行ベクトルと呼ばれる(𝑥1, 𝑥2)のように横向きに成分を表示する形式だったが,大学以降の数学(もちろん機械学習でも)においてはベクトルは列ベクトルと呼ばれる縦型の表示がスタンダードである.論文や書籍などでは縦型に書くとスペースを取るので,横向きに書いてそれを転置( 𝑇 で表現している)することで列ベクトルにするというのが一般的に行われている.
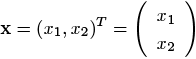 (2)
(2)
機械学習でやることは,このように2次元データxを用意し,モデルの形も指定することである.このモデルでは3つのパラメータ(𝑤1, 𝑤2, 𝑏)があるが,とりあえず最初は適当に決めて,実際のデータを入れてみる.そうするとモデルは何かしらの値を出力するはずであり,これがモデルの予測値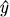 である(予測値はハットと呼ばれる記号^を使って表す).
である(予測値はハットと呼ばれる記号^を使って表す).
もちろん適当に決めてしまったパラメータなので,実際のの値とは大きく異なるであろう.そこで,損失関数(loss function)や目的関数(objective function)と呼ばれる,一種の「誤差」を定義して誤差を計算してみよう.誤差𝑙の定義は研究者自ら行う必要があるのだが,よく使われる関数はいくつかあり,例えば実際の値と予測値の差の2乗を「誤差」にするということが考えられる.
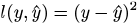 (3)
(3)
「学習」させたいデータxは1点だけではなく通常複数.例えば𝑛個のデータがあり,それぞれの正解データと予測を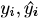 のように表せば,誤差𝑙()の平均は
のように表せば,誤差𝑙()の平均は
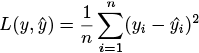 (4)
(4)
と書ける.これは平均二乗誤差(mean squared error,MSE)と呼ばれる代表的な損失関数であり,本書でも随所に使われている.
さて,今は3つのパラメータ 𝑤1, 𝑤2, 𝑏 を適当に決めたのだった.機械学習でやりたいことは,これらのパラメータを最適化することであり,もっと言えばモデルの予測値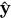 が正解の値yに近づくようなパラメータの値にしたいのだ.つまり,(4)に示す
が正解の値yに近づくようなパラメータの値にしたいのだ.つまり,(4)に示す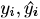 は 𝑤1, 𝑤2, 𝑏 をもとに計算されるので,𝐿はパラメータw = (𝑤1, 𝑤2, 𝑏)𝑇 の関数なのだ.「誤差」が最も小さくなる,つまり(4)を最小化するような最適なパラメータwの値をそれぞれ求めることになる.
は 𝑤1, 𝑤2, 𝑏 をもとに計算されるので,𝐿はパラメータw = (𝑤1, 𝑤2, 𝑏)𝑇 の関数なのだ.「誤差」が最も小さくなる,つまり(4)を最小化するような最適なパラメータwの値をそれぞれ求めることになる.
変数が1つしかない関数y = 𝑓 (x)の場合であれば,どのようなxのときにyが最小値を取るか,ということは高校数学で習った微分をすれば求められる(場合もある)のだった.変数が多くなっても基本的な考え方は同じで,高校で習った微分の延長である偏微分と呼ばれる方法をベースにして,もし変数間に何か特殊な条件があればそれもラグランジュの未定乗数法注6)などで加味したうえで最適なパラメータw*(見つけ出した最適なパラメータは*を付けて表示することが多い)を見つける.wの関数である誤差𝐿(w)を最小化するwを探す,というのは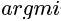 という記法を使って次のように文献では書かれる.
という記法を使って次のように文献では書かれる.
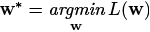 (5)
(5)
この最適なパラメータを決定するところを,いわば暗黙のうちにやってくれるのが機械学習というわけだ.研究者が行うことは2つあり,1つはデータと答えのペア(x, y)をたくさん用意することだ.答えをもとにパラメータを学習していくわけであるから,答えyは「教師」と呼ばれ,このような教師がいる学習の仕方を教師あり学習(supervised learning)と言う.
研究者が行うことの2つ目は,モデルの形,つまり𝑓(x)の形を決めることだった.例えば線形回帰を使うにしても,3次の線形回帰ではなく1次の線形回帰にする,といった具合である.モデルの形を決めればパラメータの値はデータを学習して最適な値に設定できるのだが,逆に言えばモデルの形はデータから学習できない.このように学習によって最適化できないパラメータ(3次なのか1次なのか,など)のことを,ハイパーパラメータ(hyperparameter)と言う.ハイパーパラメータを研究者が指定すれば,パラメータは自動でデータから学んで最適なものにしてくれる,それが機械学習の概略だ.
1.2.4データを丸暗記してはいけない
「学習」とはつまるところデータからパラメータを自動推定することであることは説明した通りだ.そして手元に用意したデータに対して「完璧」なモデルが作れたとしよう.しかしそういう「完璧」なモデルは,しばしば新しいデータに対して的外れの予測をしてしまうことがある.
例として,線形回帰モデルにおいて1次関数と60次関数のそれぞれでパラメータを最適化した結果を図1.3に示す.1次関数モデルは直線なので,もちろんデータを「完璧」に予測できていないのに対し,60次関数モデルはすべてのデータ点が曲線上に乗っているため,少なくともこれらのデータについては「完璧」なモデルと言える.
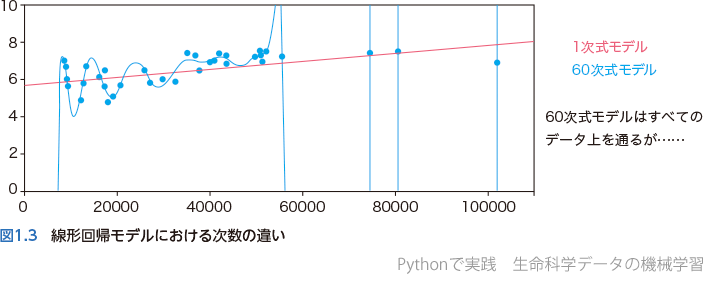
さて,実際にはどちらのモデルのほうがいいだろうか? 60次関数モデルだと学習に使ったデータ以外の新しいデータに対してほとんど対応できそうにないだろう.機械学習の本質は手元にあるデータを予測したいのではなく,まだ見ぬ新しいデータに適用できるようにすることなのだ.その点では1次関数モデルのほうが「まし」のように見えてくる.
学習に使うデータのことを訓練データ(training data)と言うが,実は訓練データに対して「完璧」なモデルというのはいくらでも作ることができる.図1.3の60次関数モデルがいい例だ.パラメータの多いモデルは自由度が高いということを説明したが,自由度が高いということは柔軟性があるということであり,もっと言えば訓練データを「丸暗記」することができるのだ.しかしながら,何も理解せずに単に「問題の答えを丸暗記」しているだけならば何の意味もない.丸暗記型だと少し違う問題がテストに出てきたら何も太刀打ちできないのは,受験生だけでなく機械学習も同じである.そのため,機械学習モデルの性能を評価するうえでは,訓練データで学習した後に,それとはまったく別のテストデータ(test data)で検証する必要がある.訓練データを過剰に学習しすぎてしまうことを過学習(overfitting)と言うが,過学習せずにテストデータに対しても訓練データとある程度同等の性能が発揮できるモデルが望ましい.そのような高い
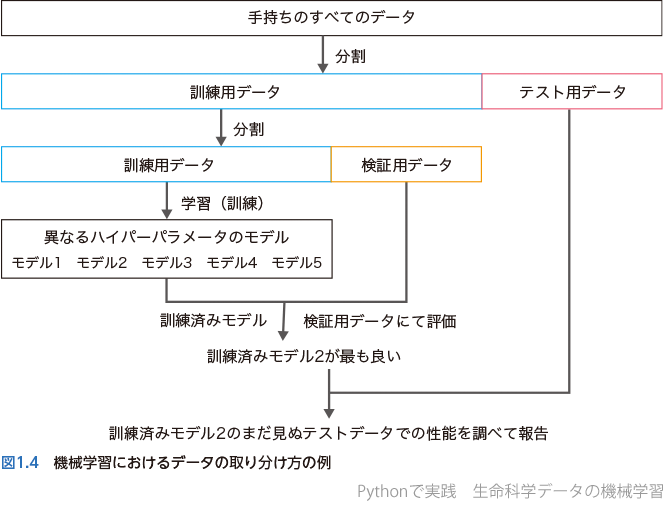
そのために,機械学習においては用意したデータすべてを使って学習してはいけない.まず最初に,訓練データとテストデータを分けて,訓練データのみで学習を行う.そして学習が完了したら,あらかじめ分けておいたテストデータでそのモデルの性能を調べるのだ.もっと言えば,モデルには人が指定する必要があるさまざまなハイパーパラメータがあり,どのハイパーパラメータが良いかはやってみないとわからない.そこで,訓練データをさらに「訓練」と「検証」データに分けて,さまざまなハイパーパラメータでのモデルを「訓練」データセットで学習させ,どのハイパーパラメータが良いかを「検証」データで比較し,最も優れるモデルについてこれまで一度も見ていないテストデータで性能を調べるということを行うのだ.大事なことは,テストデータを使うのは最後の1回だけであること,この時点では新しく学習をするのではなく,すでに学習したモデルの汎化性能を確認するということだ.もちろん真の意味での「テスト」はまだ見ぬデータに対するモデルの性能であるが,取らぬ狸の皮算用という言葉にもあるようにそれらのデータがないのにそのようなことを言っても何もできない.そこで手元にあるデータの一部を「テスト」として取り分けておき,最後のモデルの性能評価だけに使うことで,まだ手元にないデータに対するモデル性能の近似と見なすのだ.機械学習に共通する典型的なフローチャートを示す(図1.4).
どのようにして過学習を抑えるのかということについては,さまざまな工夫がある.例えば線形回帰の例で言えば,パラメータの自由度が大きくなりすぎないように制約を加えることもできる.(4)で定義する誤差に,パラメータwの大きさに関する項をペナルティとして加えるのだ.そのような正則化項(regularization)と呼ばれるものを追加することで,パラメータを大きくする(より自由度の高いモデルを作る)ことによるペナルティと,訓練データに対する予測性能の向上を天秤にかけて最適化を行うことができ,代表的な方法としてリッジ回帰(ridge regression)やラッソ回帰(lasso regression),あるいはその中間であるelastic net法などが知られている.
当然ながら,過学習の反対である未学習(underfitting,過小学習とも),つまり訓練データに対してもモデルの性能が低いということは避けなければならない.「いい塩梅」で学習させる必要があるのだ.
文献
- Jumper J, et al:Nature, 596:583-589, 2021
- AlQuraishi M:Curr Opin Chem Biol, 65:1-8, 2021
- Das R & Baker D:Annu Rev Biochem, 77:363-382, 2008
- Senior AW, et al:Nature, 577:706-710, 2020
- Marks DS, et al:PLoS One, 6:e28766, 2011
- Mosalaganti S, et al:bioRxiv, doi:10.1101/2021.10.26.465776, 2021
- McCulloch WS, et al:Bull Math Biophys, 5:115-133, 1943
- Chen Y, et al:Bioinformatics, 32:1832-1839, 2016
- Liang M, et al:IEEE/ACM Trans Comput Biol Bioinform, 12:928-937, 2015
- Xiong HY, et al:Bioinformatics, 27:2554-2562, 2011
- Jaganathan K, et al:Cell, 176:535-548.e24, 2019
- Kelley DR, et al:Genome Res, 26:990-999, 2016
- Avsec Ž, et al:Nat Methods, 18:1196-1203, 2021
- Alipanahi B, et al:Nat Biotechnol, 33:831-838, 2015
- Kulmanov M, et al:Bioinformatics, 34:660-668, 2018
- Sanderson T, et al:bioRxiv, doi:10.1101/2021.09.20.461077, 2022
- Zou Z, et al:Front Genet, 9:714, 2018
- Li S, et al:Biochim Biophys Acta Proteins Proteom, 1868:140422, 2020
- Gentile F, et al:Nat Protoc, 17:672-697, 2022
- Shimizu H, et al:bioRxiv, doi:10.1101/2021.09.25.461785, 2021
- Stokes JM, et al:Cell, 180:688-702.e13, 2020
- Jayatunga MKP, et al:Nat Rev Drug Discov, 21:175-176, 2022
- Chuai G, et al:Genome Biol, 19:80, 2018
- Wang D, et al:Nat Commun, 10:4284, 2019
- Allen F, et al:Nat Biotechnol:doi:10.1038/nbt.4317, 2018
- Shen MW, et al:Nature, 563:646-651, 2018
- Song M, et al:Nat Biotechnol, 38:1037-1043, 2020
- Kim HK, et al:Nat Biotechnol, 39:198-206, 2021
- Alley EC, et al:Nat Methods, 16:1315-1322, 2019