概論
がん研究におけるAI活用の重要性
Importance of AI technologies for cancer research
浜本隆二
Ryuji Hamamoto:Division of Molecular Modification and Cancer Biology, National Cancer Center Research Institute(国立がん研究センター研究所がん分子修飾制御学分野)
ディープラーニング(深層学習)技術の登場,GPU(graphics processing unit)を中核とした計算機環境の向上,およびデータベースの拡充によるビッグデータ利活用の簡便化などの要因により,現在,人工知能(artificial intelligence:AI)技術に大きな期待が寄せられている.2018年1月,Google社のCEOであるSundar Pichai氏は,米国の番組に出演し,“現在,人類が取り組んでいるAIの開発は人類史上で最も重要な任務の一つ.火や電気よりも重要になるかもしれない”とAIの重要性を語った.実際Donald Trump米大統領は2019年2月に,大統領令として“American AI Initiative”を発し,米国がAI開発において世界を牽引するという強い意志を示した.また中国政府は2017年7月,AI技術とその応用に関して3段階の政策を発表し,AIイノベーションで世界のリーダーをめざすことを世界に示した.このように,列強がしのぎを削ってAI開発に取り組んでいるなか,わが国においても,2016年に内閣府が策定した第5期科学技術基本計画のなかで“Society 5.0”として,未来社会のコンセプトが明文化され,その実現においてAI技術が重要な基盤技術として位置づけられている.現在,AIはさまざまな分野に応用されているが,ライフサイエンス分野も重要な領域の一つと考えられ,メディカルAI研究が世界レベルで推進されている.本特集においては,メディカルAI研究のなかでも,がんに関連した話題に焦点をあて,学術的側面から見た最先端の知見を,国内第一線の先生方からご紹介いただく.
はじめに
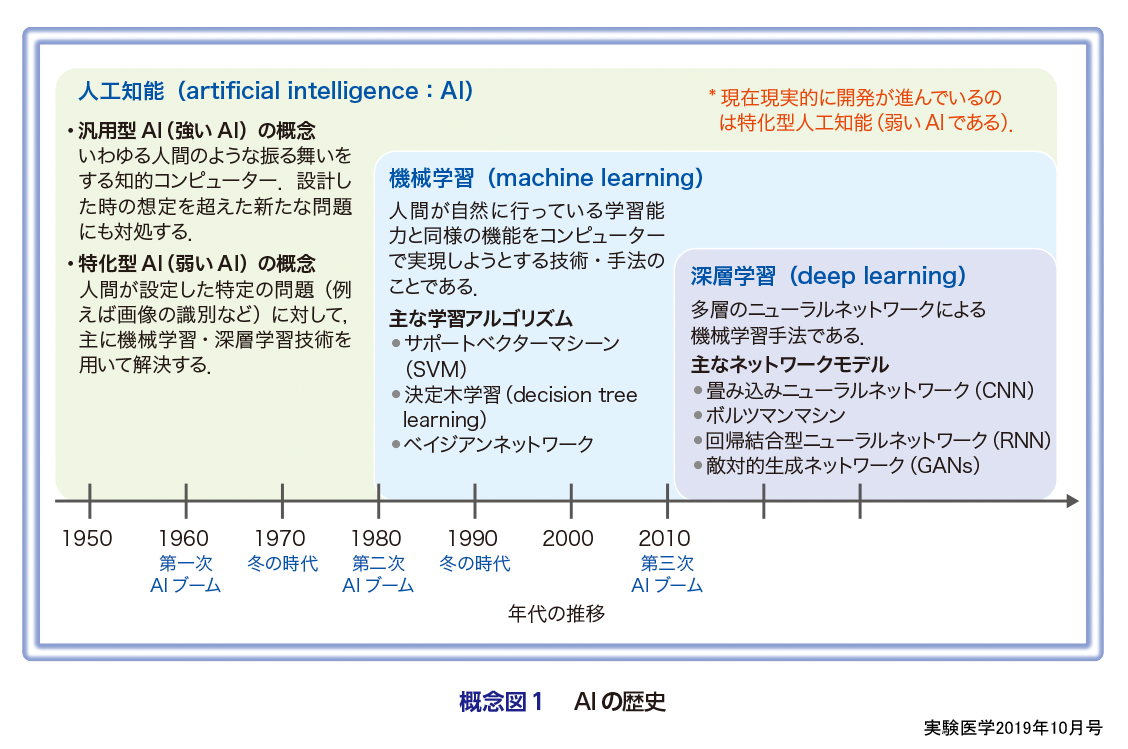
人工知能という概念は古くから提唱されていたが,実際に学術分野の専門用語として“artificial intelligence:AI”という用語がはじめて使用されたのは,1956年米国ニューハンプシャー州にあるダートマス大学で開催されたダートマス会議でJohn McCarthyにより提案されたことが発端と認識されている.概念図1にAIの歴史を示すが,AIという言葉が使用されはじめた1950年代後半,1960年代初頭当時は専門家の間でも比較的楽観的な予測がなされていた.つまり10〜20年後には,設計したときの想定を超えた新たな問題にも対応できる,いわゆる人間のようなふるまいをする汎用型AI(強いAI)が実現すると考えられていた.しかし,汎用型AIはいまだに完成されておらず,現在,現実的に開発が進んでいるのは,人間が設定した特定の問題に対して,主に「機械学習」技術・「深層学習」技術を用いて解決するという,特化型AI(弱いAI)である(概念図1).また,1970年代に入ると,AIはいわゆる迷路等の“toy problem”は解決できても,現実の複雑な問題には対応できないという認識が広がり,AI研究者は批判と資金縮小に晒され,AI冬の時代を迎えることになる.
1980年代に入り,AIプログラムの一形態である“エキスパートシステム”が世界中の企業で採用されるようになり,第二次AIブームとよばれるAI活況の時代を再度迎えた.第二次AIブームにおいては,“機械学習(machine learnign)”とよばれる,人間が自然に行っている学習能力と同様の機能をコンピューターで実現しようとする技術・手法の開発が進み,サポートベクターマシン(SVM),決定木学習(decision treeなど),またベイジアンネットワークなどさまざまなアルゴリズムが開発された(概念図1).しかし研究者や政府が掲げる目標・理想と,実際にAIが可能なこととの間にギャップがあることが露呈されはじめ,またしてもAI研究者は批判と資金縮小に晒され,2回目のAI冬の時代を迎えることになる.
2006年にGeoffrey Hintonによりオートエンコーダーを利用した“深層学習(deep learning)”技術が開発され,また2010年にはインターネットを流れるデータ転送量の増大を受けビッグデータという用語が提唱されるなど,AI研究に再び注目が集まる土壌が形成されはじめた.特に2012年のILSVRC(ImageNet Large Scale Visual Recognition Challenge)という画像認識精度を競うコンペティションにおいて,深層学習技術を用いて解析した手法が従来手法を大きく凌駕したのをきっかけに技術開発が加速し,ついには人間を超えるような性能を達成できるようになった1).それによってAI技術に大きな注目が集まり,第三次AIブームとよばれる時代に突入し現在に至っている.第三次AIブームの火付け役は深層学習技術の登場が大きいと考えられているが,同時に計算機環境の向上(特に安価で高性能のGPUが入手可能になったこと)もあげられている.第三次AIブームと以前のAIブームとの一番の違いは,すでにAIの技術が社会のさまざまな分野へ実装されていることがあげられる.顔認証・音声認証・自動運転にはAI技術が活用されており,また米国においては,アメリカ食品医薬品局(FDA)に認可されたAI搭載医療機器は20近くにおよび,本邦においても昨年はじめてAI搭載医療機器が薬事承認を受け,販売がはじまっている.以上のことから現在はブームという枠組みを超え,今後もますます社会に実装されていくAIと人間がどのように向き合い,いかにAIを人類の健康と幸福のために活用していくかという戦略を,真摯に考えていく段階に入っていると考えている.
1がん研究におけるAI活用の重要性
さまざまな分野で活用されるAIであるが,特にがん研究において機械学習技術・深層学習技術が重要である理由は後述の4つであると考えている.
- マルチモーダル学習が可能であること
- マルチモーダル学習とは異なる種類のデータ(モーダル)を統合し入力として扱う手法.
- これらのデータをどのように組み合わせて解析するかはAIが学習の過程で自動に取得できる.
-
マルチタスク学習が可能であること
- マルチタスク学習とは複数の異なるタスクをモデルの一部を共有して同時に学習する手法.
- モデルの共有により学習の効果をあげることができる.
- 表現学習および半教師あり学習が可能であること
- 大量のラベルなしデータからデータの表現方法を獲得する手法(詳細は瀬々の稿,山本の稿,小林の稿参照).
- 少量のラベルありデータから学習ができる.
- 階層的な特徴量の自動獲得が可能であること
- 入力の高次の相関を捉えることができる.
従来の解析手法ではこのような特徴をすべて兼ね備えることが難しかったが,現在のAI技術はこれら4つの特徴を兼ね揃えており,がんデータ解析に適していると考えられる.特にがんという複雑な疾患の本態解明には,さまざまなモダリティの異なる多層的なデータを統合的に解析する必要がある.また疾患の転機を考察するためには,経時的な変化も考察する必要がある.このようなマルチモーダル学習・マルチタスク学習は,深層学習技術が強みとしている点で,“木を見て森を見ず”的ながん研究ではなく,膨大なデータから俯瞰的に疾患の特徴・本質を探究し,なるべく研究者の主観を排した解釈が可能となる.例えば,ワシントン大学のLeeらは,急性骨髄性白血病(AML)患者に関する,膨大なオミックスデータ(遺伝子発現量データ,遺伝子変異データ,DNAメチル化データ,遺伝子機能データ)と抗がん剤感受性データを組合わせ,AIを用いて解析することで,薬剤感受性遺伝子の同定に成功している2).
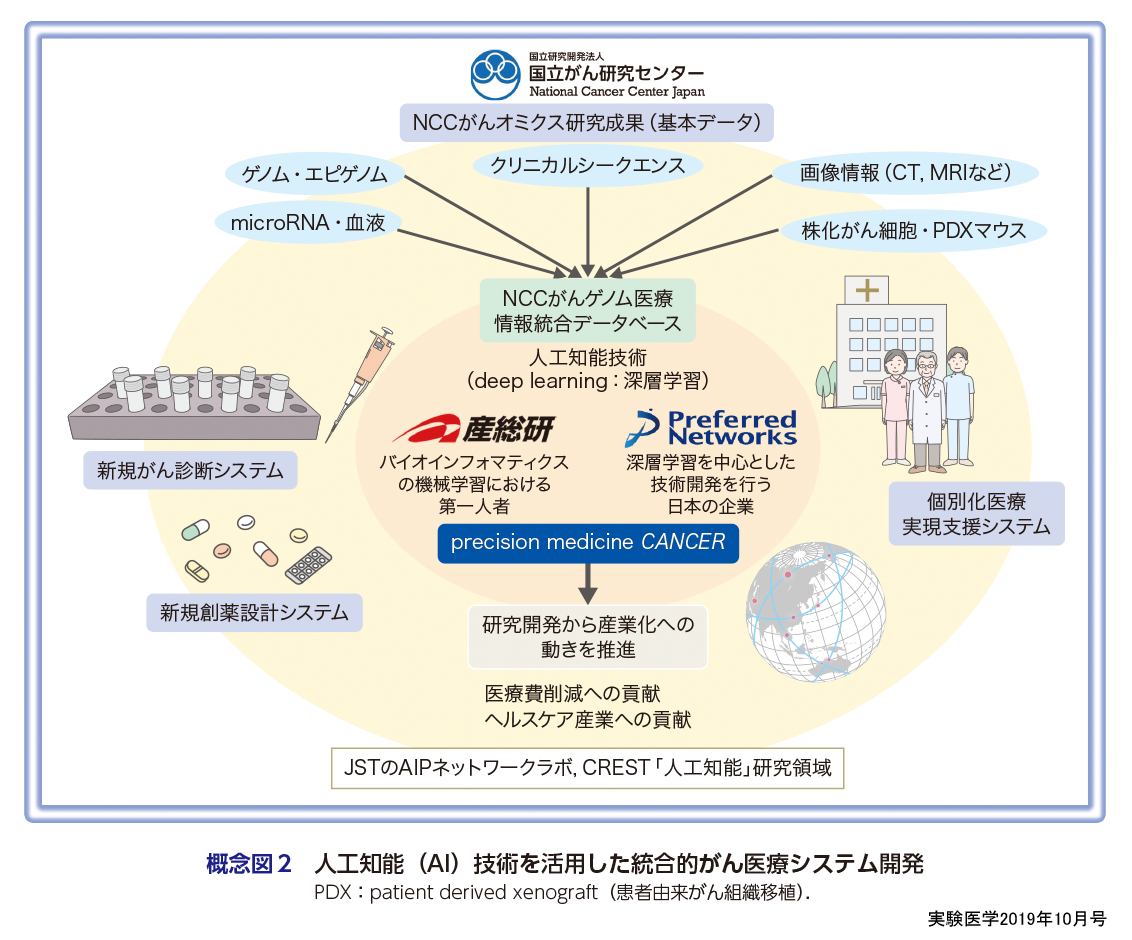
このようにがん研究におけるAIの強さが認識され,2016年から国立研究開発法人科学技術振興機構(JST)の戦略的創造研究推進事業CRESTの一課題として,“人工知能(AI)を活用した統合的がん医療システム開発”プロジェクトがスタートした3)4).プロジェクトの概念を概念図2に示すが,さまざまながんのオミックスデータ(ゲノム・エピゲノムデータ,医用画像データなど)を臨床情報と統合して,AI(機械学習・深層学習)技術を活用して解析し,がんの診断やprecision medicineの実現,さらに創薬へ応用することを目標としている.
本プロジェクトにおいてわれわれがはじめに重点的に行ったのは,医療リアル・ワールド・データ(RWD)を効率的に収集するシステムの構築とデータ取り扱いガイドラインの策定である.AI研究というと華やかなイメージを抱きがちであるが,実際は泥臭い地道な活動がほとんどである.特に近年,急速にアルゴリズムが発展しパッケージ化が進んでいることにより,AI自体の性能ももちろん重要であるものの,いかに高品質の構造化されたデータを効率的に集めるシステムを構築するかが,がんを含めたメディカルAI研究の成功を握る大きな鍵となっていると感じている.医療AI研究というと,どうしてもAI技術による解析部分のみに焦点を当てがちであるが,個人的には高品質のデータを収集するシステムの構築,およびAI解析に適したデータの構造化がたいへん重要であると考えている.例えば過去の研究状況を精査してみると,第二次人工知能ブームには優れた機械学習技術がすでに開発されており,AIの利活用の目的も現在と大きく変わらない.しかし評価されることなく衰退した原因として,AI開発において重要な「知識」と「推論」のうち,「知識」にあたるデータベースが当時は充実していなかったという事情などにより,AIの社会における有用性を示すことができなかった点があげられている.過去の失敗と同じ轍を踏むことなく当該分野を健全に発展させていくためには,AI解析を志向した構造化されたデータベースの拡充など,地に足を付けた地道な取り組みがとても重要であると考えている.
また,がん研究者の立場として,機械学習・深層学習技術を用いた解析に取り組んできた実感として,近年のAI技術(特に深層学習技術)は非線形に主成分分析を行ううえにおいて有用性がある一方,因子分析や因果関係を分析することは不得手であると感じている.例えば医用画像から特徴を抽出し,病態の分類や遺伝子型の推測を精度高く行うことが可能であるが,結論を出す過程を論理的に説明することが困難である(現在,判断根拠を理解するさまざまな手法も開発されつつある).一過性のブームに乗じて何でもかんでもAIで解析するというよりは,AIの特性を冷静に判断しその有用性を存分に活かし,他の統計学的手法も有効に活用しながら,目的型研究を推進することが,過剰にAIというものに期待を抱くことなく,健全にAI研究の質を上げていくことにつながると強く感じている.
2がん研究におけるAI活用の現状と今後
本誌は基礎医学・生物学研究者を主な対象としているため,AI搭載医療機器の社会実装に関する最新の情報は他の総説などに譲るとして,ここでは基礎研究の側面に焦点をあて論じていく.
近年のAI研究の勃興は深層学習技術の登場が一つの要因であり,深層学習技術は画像解析に強いため,医用画像(内視鏡画像・放射線画像・病理画像など)解析・細胞画像解析などに積極的に活用されている5)〜7)(山田らの稿,山本の稿,小林の稿).実際本邦においてもAMEDの研究事業として,学会主導による診断画像のデータベースを構築,AIを活用した診断・治療支援により,医療の質を向上させるプロジェクトがスタートしている.AI技術を用いた画像認識は基本,分類(classification)と検出(detection)の2つに大別される.分類(classification)はさらに物体分類(何が写っているかを分類する)とシーン認識(全体として何の画像であるかを認識する)があり,検出(detection)は物体検出(どこに何が写っているかを検出する)と領域の検出〔領域(segmentation)を検出する〕に分けられる.画像のヒストグラム,形状,テクスチャ,周波数成分などの画像特徴量を網羅的に定量化することで,研究者の主観をなくし,客観的な数値化されたデータとして解析することができるため,バイアスのない研究成果を出すために有用である.実際腫瘍の画像的特徴を余すことなく“言語化”することは困難であり,画像特徴量をコンピューターにより網羅的に計算することで,腫瘍の表現型を客観的かつ遺漏なく捉えることが可能になる.最近は病理画像や放射線画像を,AI技術を活用して解析することにより,遺伝子型や臨床的特徴(悪性度や予後など)を高精度に予測できることが報告されており,単に異常検知(anomaly detection)の研究からAI技術を用いた質的診断をめざした研究が進んでいる(小林の稿).
画像解析以外にゲノム・エピゲノム研究においてもAI技術は活用されている(瀬々の稿).特にゲノム・エピゲノム解析は現在,次世代シークエンサー(next generation sequencing:NGS)による解析が中核となっており,日々膨大な量のデータが蓄積されている.特に全ゲノム解析(whole genome sequencing)で得られるデータは膨大で,1検体あたり100 GB程度となる.もちろんこのデータのなかには潜在的に多くの情報を含んでいると予想されるが, 30億塩基対(60億塩基)という量の情報を網羅的に解析するのは人間の能力を超えており,AI技術の活用が求められている.実際今年4月に,ラディチルドレンズ・ゲノム医学研究所のスティーブン・キングスモア博士が率いる研究チームは,全ゲノム解析配列検査にAIを導入することで,同日遺伝子診断が可能になっていることを報告している8).また,precision medicineの推進には,NGS解析で得られた個々の変異情報を,過去の文献や,ClinVarやClinGenなどのデータベースと照合し,意義づけを行う必要がある(エキスパートパネルとよばれる).このステップにAI技術を導入する試みも開始されている(井元の稿).さらに膨大な医療RWDを,AI技術を用いて統合的に解析し,創薬に応用する試みもはじまっている(田中らの稿).創薬において,非臨床試験におけるマウスを用いたデータをもとに臨床試験を開始し,フェーズ2で脱落するという「ネズミでは効くが,ヒトでは効かなかった」(Ph2 attrition)が問題になっている点もあり,今後,膨大なヒトの医療RWDをAI技術を用いて解析することによる新規創薬標的の探索は重要な研究であると考えている.
3AIを活用した研究の具体例
本特集号の読者の方々のなかには,AIに興味がありご自分の研究にAIを活用したいと考えているものの,どのように研究を進めてよいかわからない方がいらっしゃると思うので,具体例をもとに研究の概要を示したい.
まず,ラボで細胞画像をAIで解析し,細胞の種類を予測するタスクが与えられた場合を考える.最初に重要なステップは,学習用データの準備である.現在最先端のAI研究は教師なし学習に注目が集まっているが,ここでは教師あり学習をご紹介する.その場合は,画像にアノテーション付け(赤血球/白血球/血小板,アポトーシス/セネッセンス/ネクローシスなど)を行い,画像とそれぞれの画像に対応した,アノテーション情報(細胞の種類および細胞を囲むbounding boxの座標など)をXMLファイルに格納する.続いて訓練用のアルゴリズムを選択することになるが,現在日進月歩でアルゴリズム開発が進んでいるため,常に自分の目的と類似の論文を読み,最適と考えられるアルゴリズムを選択して,学習を行う必要がある.物体検出に関しては,1段階の処理で構成されたアルゴリズムであるAlexNet, ResNet, GoogLeNet, R-CNNなどのsingle stageタイプと,Fast R-CNN,YOLO,YOLO9000,Masked R-CNNなどのtwo stageタイプなどさまざまなモデルがあるが,一般にsingle stageタイプの方が高速と言われ,two stageタイプのものの方が精度が高い,と言われている.このようなトレードオフに関しては,さまざまな物体検出手法を比較調査した論文も発表されている9).学習が終わったら,得られたモデルをテストデータセットで評価する.実際の応用で物体検出器を訓練する場合には,まずは有名なモデルを使って学習を行ってみて結果をつくったあと,その結果とデータを突き合わせて,モデルの予測の傾向やデータセット自体の特徴などを吟味する段階が重要となる.
続いて,NGSで得られた塩基配列をAIを用いて解析する例を説明する.塩基配列データを扱うためには,現在,主に3つの戦略がある.1つ目は,配列中の順序情報を捨てて,配列をその特徴の集合とみなす手法で,bag of words(BoW)表現とよぶ.このBoW表現は,特徴に充分な情報が含まれていれば強力な手法であるが,DNA配列のような4種類の文字からなる配列や,その部分配列だけではその特徴を捉えることは困難である.2つ目は,配列中の要素を左から右に順に読み込んでいく手法で,RNN(recurrent neural network)を用いて解析を行う.RNNはその計算方式から,計算の途中結果をすべて固定長の内部状態ベクトルに格納する必要がある.遠距離間の関係を捉えようとすると,多くの情報を覚えておかなければならないが,状態ベクトルサイズは有限であるため,遠距離間の関係を捉えることが困難となってしまう.3つ目は配列データを一次元の画像とみなし,画像処理のときと同様にCNN(convolutional neural network,山本の稿参照)を用いて解析する手法である.CNNはRNNの場合と違って,各位置の処理を独立に実行できるため,並列に処理することができる.また,dilated convolutionを使うことで各位置の処理は,遠距離にある情報を直接読みとることができる.この手法を用いることで,数百種類のヒトの細胞型から得られた数千のChIP-seq, DNase-seqのデータセットから得られたDNA塩基配列を入力として,CAGEの結果計測されたmRNAの発現量を推定できることが報告されている10).
DNA塩基配列をAIで解析するうえで注意が必要なのが,DNA塩基配列の長距離相互作用である.染色体の構造上(DNAは複雑に折り畳まれた様式で存在する),塩基配列(二次元)上の並びとしては遠く離れた2つの領域が,空間(三次元)的には近い距離に位置し,遺伝子発現などに影響を与えることが知られている.この観点では,モデル選択の重要性もさることながら,Hi-C解析などでゲノムの三次元空間内の立体構造を明らかにし,その情報を入力情報として入れる必要があると感じている.要は,質の高い“WET”な実験と質の高い“DRY”の実験が融合されて,はじめて質の高いAIを用いた医学研究成果を出すことが可能になる,と私は判断している.がんを含めた複雑な生命現象を解明するには,これまで蓄積されてきた情報だけではまだまだ不十分であり,AI技術が進化すれば生命現象は解明されるという,AIに対する過剰な期待は危険で,従来行ってきた基礎医学研究もきちんと今後も発展させ,その特性をかんがみながら,効率的にAI技術を活用するという,地道な取り組みが現在重要であると感じている.
おわりに
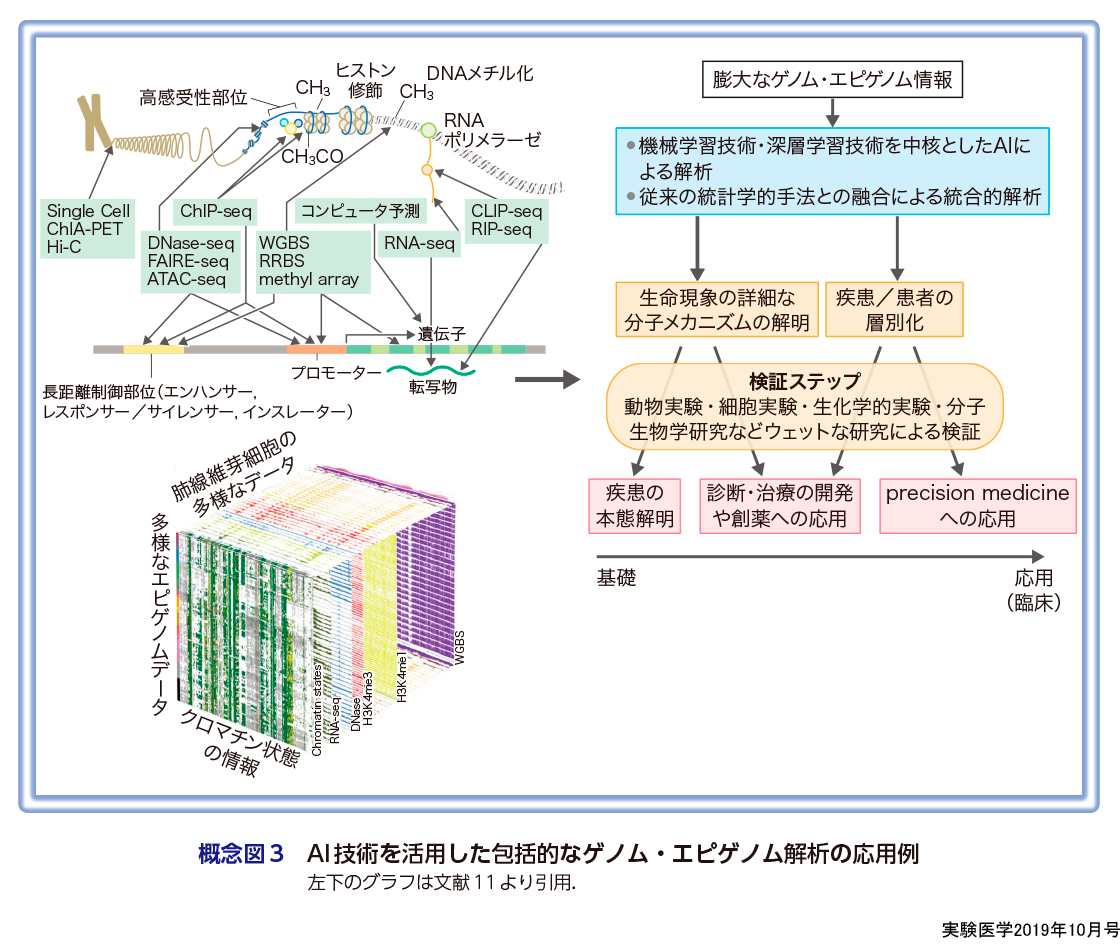
がんという疾患は不均一(heterogeneous)な集団であり,真のprecision medicineの実現には,個々のがんの特性を,さまざまな臨床情報やさまざまなモダリティのオミックスデータを統合化し,マルチモーダルに解析する必要があると考えている(概念図3).前述のようにマルチモーダル学習・マルチタスク学習はAIが強みとしている部分で,今後AIを積極的に導入すべき必要性を感じている分野である.これまでは,ゲノム解析,エピゲノム解析,プロテオミックス解析,医用画像解析という各モダリティのデータが単独(単層)で解析されてきたが,この手法であると,本質を見抜けない可能性があると考えている.さまざまなモダリティのデータを詳細な臨床情報と合わせ,さらに疾患の転機として重要な時間的な変化(経時変化)も統合し,AI技術を用いて統合的に解析することで,がんの本態解明から創薬・precision medicineへの応用へ,一気通貫の研究ができる可能性があると考えている(概念図3).
しかし,技術的に解決すべき問題もいまだ散見されるのも事実である.例えば医学データというのは,サンプル数(number)に比べてパラメーター(parameter)が非常に多く,従来の統計モデルでは不定問題となる(例:SNPsでは数百万次元).この問題は新NP問題と定義され,特にゲノム研究分野におけるさらなるAI導入のための障壁の一つとなっている.また希少疾患などではそもそも対象疾患で取得されるデータは少量であるという問題があり,多くの解析データを必要とする深層学習技術の使用が困難である.これらの問題を解決する研究も積極的に行われており,今後改善されていくことが期待されるが,AIを活用したがん研究を効果的かつ効率的に進めるためには,医学・生物学研究者と情報工学の研究者双方が歩み寄り,互いの研究を深く理解しあうことが最重要であると感じている.医学・生物学的側面および情報工学的側面を両輪として研究を進めることにより,“がん”という人類共通の敵に分野を超えて立ち向かい,がんで苦しんでいる患者さんに,少しでも希望を与えていくことが理想であると考えている.前述のCRESTプロジェクトでは,医学・生物学分野の専門家と情報工学の専門家が有機的に連携することで大きく研究が進展し,また共通の課題を認識し解決することを目的に,日本メディカルAI学会の創設にも発展した.日本メディカルAI学会には医学・生物学分野や情報工学の専門家以外にも,法律の専門家や生命倫理の専門家も入会されており,活発な議論がなされている.新しい研究分野で,また社会実装も近い分野であることから,社会における位置付けを含め,多角的な議論が必要である分野であることを実感している.
最後に,本稿執筆にあたり貴重なご助言をいただいたPreferred Networksの岡野原大輔博士,国立がん研究センターの金子修三博士,浅田健博士に感謝の意を表し,筆をおく.
文献
- He K, et al:Proceedings of the 2015 IEEE International Conference on Computer Vision(ICCV),1026-1034, 2015
- Lee SI, et al:Nat Commun, 9:42, 2018
- 浜本隆二:人工知能を用いた統合的ながん医療システムの開発.平成28年度戦略的創造研究推進事業(CREST),2016
- 浜本隆二:AI技術を用いた統合的ながん医療システムの開発と解決すべき問題点.最新医学,74:384-391, 2019
- 山田真善,et al:AIによる内視鏡画像からの病変部位の検知技術の開発.最先端医療機器の病院への普及展望と今後の製品開発(技術情報協会),2018
- 小林和馬 & 浜本隆二:人工知能技術によって変革される放射線医学.ファルマシア,54:875-878, 2018
- 脇田明尚,et al:深層学習の放射線治療への応用.Isotope News, 758:12-15, 2018
- Clark MM, et al:Sci Transl Med, 11:doi:10.1126/scitranslmed.aat6177, 2019
- Huang J, et al:arΧiv.org, arXiv:1611.10012, 2016
- Kelley DR, et al:Genome Res, 28:739-750, 2018
- Kundaje A, et al:Nature, 518:317-330, 2015
著者プロフィール
浜本隆二:2001年東京大学医科学研究所助手,’06年ケンブリッジ大学腫瘍学部Honorary Visiting Fellow,’07年東京大学医科学研究所助教,’12年シカゴ大学医学部准教授を経て,’16年より国立研究開発法人国立がん研究センター研究所分野長,東京医科歯科大学大学院医歯学総合研究科連携大学院教授,戦略的創造研究推進事業CREST研究代表,’17年より国立研究開発法人理化学研究所革新知能統合研究センターチームリーダー,’18年より一般社団法人日本メディカルAI学会代表理事,内閣府/官民研究開発投資拡大プログラム(PRISM)研究代表.所属学会は日本メディカルAI学会代表理事,日本オミックス医学会理事,日本癌学会評議員,日本がん分子標的治療学会評議員,アメリカ癌学会 Active Memberなど.目標:多層オミックスデータをマルチモーダルに解析することにより,がんの本態解明を行うとともに,がんの診断や抗がん剤の開発などに応用していく.