")


Q1 「統計学的に有意」とは何を意味しているのですか?
Answer
「統計学的に有意」とは「仮説」と「実際に観察された結果」との差が誤差では済まされないことを意味します.例えば,投薬による治療効果の検証では,偽薬を投与した人たちと実薬を投与した人たちとの間で症状が改善された人数を比較して,その差が偶然得られる確率を計算します.この確率が十分に低ければ有意であると表現します.有意であるかどうかの基準(有意水準)は目的によって異なり,統計的解析を行う前に設定します.
1)その観察結果は偶然か意味があるか
統計的検定の目的は,ある集団について仮説を設定し,その集団から抽出された標本の観察にもとづいて,その仮説が正しいのか否かを検証することにあります.このとき,理論上の仮説と実際の観察が厳密に一致しないのは言うまでもありませんが,知りたいのは,両者のズレがたんなる偶然による誤差の範囲内なのか,それとも誤差では済まされない,何か意味のあるものか,ということです.後者であると考えられる場合,仮説からのズレは「有意」であるとされます.
クリックして拡大
2)有意性は標本がズレを示す確率で表される
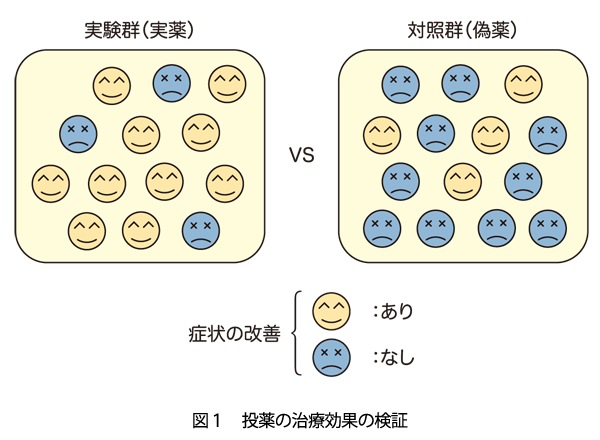
例えば,投薬による疾病の治療効果の検証を考えます(図1).実験群の患者には実薬を,対照群の患者には偽薬を投与し,症状の改善が見られたか否かを評価します.実験群と対照群でそれぞれに改善した患者としなかった患者の数を比較したとき,実験群は13人中10人の症状が改善し,対照群では14人中4人しか改善していません.この差は単なる偶然による誤差であるといえるでしょうか?
このような解析においてはカイ二乗検定が用いられます.計算の詳細は省きますが,実験群と対照群の差がない,つまり,投薬の効果はなく,症状の改善と投薬は独立であるという仮説を考えるとき,理論上のカイ二乗統計量の分布と,観察データをもとに計算されたカイ二乗統計量を比較することで,観察データからの値よりも偏った値が偶然によって得られる確率が0.033と計算されます.
この確率が小さければ小さいほど,症状の改善と投薬は独立であるという仮説が支持される可能性は低いと解釈されます.この場合,0.033は相当に「まれ」な確率なので,この仮説は誤っていたと判断せざるをえません.これを仮説が「棄却」されたと言います.
3)有意水準とタイプⅠの誤り(第一種の過誤)
ここで,0.033を「まれ」としましたが,どの程度をもって「まれ」とするかによって有意か否かが変わり得ます.この基準となる確率を有意水準といい,αと表記します.有意水準αをいくつに設定するかは研究の対象や目的によって異なり,事前に設定されなければなりません.先の例では,もし有意水準をα=0.05と定めるならば,0.033は「まれ」であり,有意であると判断されますが,もしα=0.01と定めるならば,「あってもおかしくない」,有意とは言えない,と判断されます.実用的には,検定結果の表示にあたって,複数の有意水準を用いて有意性に段階を付けることがあり,例えば0.05水準,0.01水準,0.001水準で有意ならば,それぞれ検定結果に「*」「**」「***」などとマークします.
統計的検定においては,タイプⅠとタイプⅡの2種類の誤りを犯す可能性があります.仮説と観察のズレが単なる誤差であるのに,「誤差ではない意味がある」「有意である」として,仮説を棄却してしまうのがタイプⅠの誤り(第一種の過誤,または偽陽性とも言います)です.逆に,仮説が正しくないのに仮説を棄却しないのがタイプⅡの誤り(第二種の過誤,または偽陰性とも言います)です.
先の例の,観察データからの値よりも偏った値が偶然によって得られる確率0.033は,このタイプⅠの誤りの確率であり,有意水準はタイプⅠの誤りを一定以下に抑えるための基準であるといえます.よって,統計的に有意であるからといって,絶対に誤差ではないと断定できるわけではなく,例えば有意水準α=0.05で有意という場合には,偶然に過ぎないのに,誤って意味があると判断している可能性が5%あります.逆に,統計的に有意でない場合にも,絶対に誤差だと断定できるわけではなく,あくまで偶然に起こってもおかしくないという,弱い判断になります.
統計的検定は論理学の背理法に相当し,仮説と観察のずれが有意であることをもって仮説を否定することを目的とするため,仮説が棄却された(有意である)場合と棄却されない(有意でない)場合では判断の強さが異なります.ある仮説が棄却された場合は反対の仮説が採択されますが,棄却されなかった場合は,それが何かの証明になるわけではなく,単に観察と仮説がとくに矛盾しないことが言えるだけで,その仮説が採択されるわけではありません.
クリックして拡大
4)多重比較とタイプⅠの誤りの増加
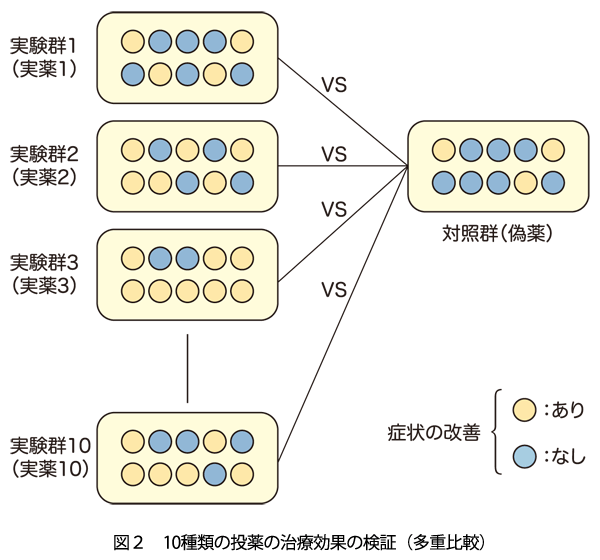
複数の検定を繰り返して,全体で有意性の判断を行うとき,タイプⅠの誤りの確率が増加するという問題があります.これが多重比較の問題です.先の投薬実験の例では,実験群と対照群の比較を1回しか行っていませんが,複数の薬剤について検証を行うとしたらどうでしょう(図2).この場合,実験群1と対照群,実験群2と対照群,実験群3と対照群…というように,単に10回の検定を行うだけでよいでしょうか?
個々の検定で有意水準を5%に設定し,その検定で偶然に有意差が出る確率を5%以下に抑えても,10回の検定全体で,どれか1つに偶然に有意差が出る確率は5%よりかなり大きくなります.
多重比較の問題への対処には,複数の比較をまとめて1つの解析と見なして,全体でのタイプⅠの誤りを一定以下に抑える方法が考えられます.例えばボンフェローニの補正法では,L回の比較を行うとき,全体の有意水準をαにしたいならば,個々の検定の有意水準をα/Lに設定します.これにより,L回の比較のうち,どれか1つでもタイプⅠの誤りを犯す確率をα以下に抑えられますが,一方で,これでは基準が厳しすぎ,検定結果が保守的になりすぎるきらいがあります.
参考図書
- 『統計学入門』(東京大学教養学部統計学教室/編),東京大学出版会,1991→ 第12章「仮説検定」に検定の基礎的概念が解説されている
- 『統計的多重比較法の基礎』(永田 靖,吉田道弘/著),サイエンティスト社,1997→ 多重比較について詳述されている