概論
医学データとスパコン,クラウド
Medical data analysis in supercomputers and the clouds
小笠原 理
Osamu Ogasawara:Bioinformation and DDBJ Center, National Institute of
Genetics(国立遺伝学研究所生命情報・DDBJセンター)
生命科学・医学系の大規模データ解析の現場では,データ量の増大による計算時間およびネットワーク転送時間の問題やセキュリティー上の課題等から,大規模データを整備したスーパーコンピューター(スパコン)やクラウド環境の整備とその利用方法の習得が必要となってきている.本特集では研究者がスパコンやクラウドを使いはじめる際の障壁がなるべく小さくなるよう,利用の基本的な考え方と利用可能なスパコン・クラウドの紹介,申請のしかた・利用支援の受け方,利用方法および応用事例を紹介する.
はじめに
近年の測定技術の進歩により,単独のラボであるか専門の研究機関であるかにかかわらず,大量かつ多種類のデータが利用可能となった.これら大量のデータを上手に研究に活用することが,遺伝性疾患関連遺伝子の特定やがんの治療・早期発見などに代表されるようなこれまで困難だったさまざまな問題に取り組む鍵となっている1).
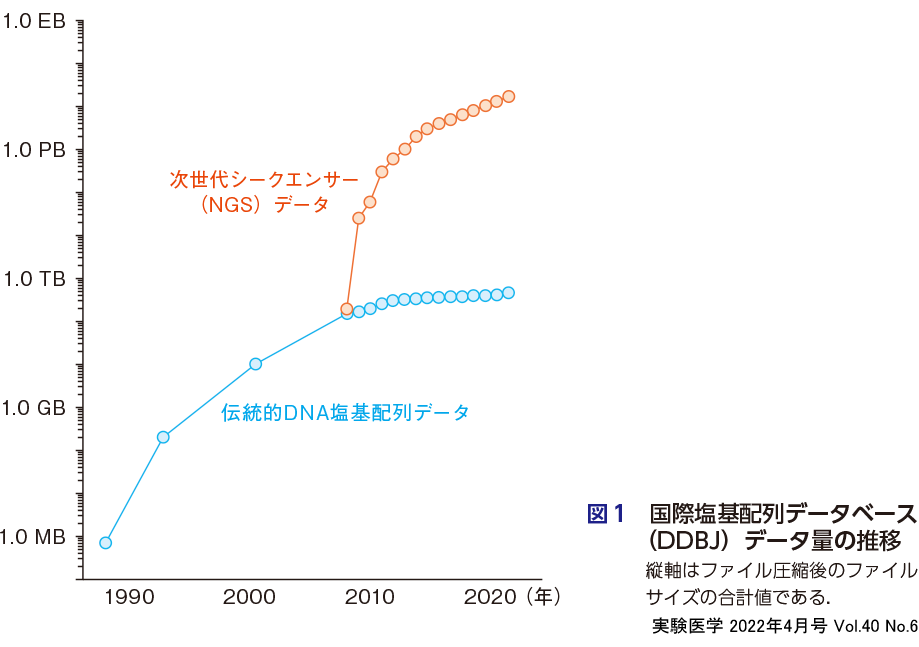
一例として国際塩基配列データベース(INSDC)のデータ量の推移を図1に示した.日本のDDBJ,米国のNCBI,欧州のEBIが共同で構築している国際塩基配列データベースは論文から参照できるDNA塩基配列データをすべて収録したデータベースであり,三極で毎日データの交換を行っているので同じデータベースの3つの公式ミラーが日米欧に存在する形になっている2).次世代シークエンサー由来のデータの収録(sequence read archive,SRA)を2008年から開始して以来データ量は急増し,それ以前と比較してデータ量は数万倍となった.こう書くとINSDC事業でデータの格納ができなくなることによる事業自体の破綻が心配されるが,データ量の伸びは2014年ごろから年率1.3倍弱程度で一定となっており3),これがストレージの単価あたり容量の伸びと大きく違わなければ近々には破綻しない.逆にデータ量を何らかの方法で減らしてもデータ量の伸びと容量の伸びがバランスしていなければ一時的な回避策にしかならず,遠からずデータベースアーカイブ事業は破綻することとなる.一方で,データの伸びが後に落ち着くなら一時的な対策は有効である.実際にSRA構築開始当初はデータ量の伸びが年率2〜6倍まで増えた時期があり,DDBJではその対策として内部の業務ソフトウェアおよび国立遺伝学研究所(遺伝研)スパコンの構成を大幅に変えることにより,予算減のなか,スパコンの性能およびストレージの容量を15倍以上に増やし,データの急速な伸びを乗り切った経緯がある4).
また,ゲノム医療の分野ではThe Global Alliance for Genomics and Health(GA4GH)の試算によると2030年までには8千3百万人の希少疾患患者,2億4千8百万人のがん患者のゲノムが診断目的で読まれると言われている5)6).
さまざまなデータが利用可能になることにより研究の可能性が広がった一方,この大規模化したデータを研究者間でどのように共有し解析すればよいか,計算インフラの問題が顕在化した.数百TBにも及ぶようなデータを各研究室の計算機にダウンロードすることは,ネットワーク通信の時間だけを考えても現実的ではない.また個々の研究室がそれだけのデータを格納し解析するだけの計算機を用意することは予算上もまたセキュリティー上も問題を多く抱えることになる.そこで,データをユーザの環境にもってくる(bring the data to the people)のではなく,ユーザの解析環境をデータがあるところにもっていく(bring the people to the data)ほうが現実的であると考えられるようになった1).すなわち大規模データを整備したスパコンやクラウド環境の整備とその利用方法の習得が,生命科学・医学系のデータ解析で必須となってきたのである.
本特集では,大規模データ解析をこれからはじめてみようという研究者の方々のために,スパコンおよびクラウドの利用のはじめ方や特有の扱い方を紹介し,がん,遺伝性疾患および新型コロナウイルスの研究を例に応用事例を紹介する.
1スパコンの活用方法
HPCI(high performance computing infrastructure)はスパコン「富岳」を中核とし全国の大学や研究機関に設置されたスパコンを高速ネットワーク(SINET)で結び,大学等のさまざまな研究分野や民間からの利用を含む多様なユーザーニーズに応えることを可能にしたしくみである.富岳はスパコンの国際性能ランキングの4部門7)~9)において2021年11月時点で4期連続で世界1位にランクする日本を代表するスパコンである.本特集では富岳およびHPCIを使いはじめる際の申請方法や利用支援の内容を含めた使い方を紹介する(須永の稿).さらに富岳は利便性の向上のためクラウド的利用に向けたプロジェクトを実施しており(富岳クラウドプラットフォーム),商用クラウドがサービスを提供しているような,解析プログラムを実行する計算機として富岳を使う形態や,逆に研究者自身の計算機(オンプレミスサーバ,プライベートクラウド)の延長として富岳に向かって計算要求を送るクラウドバースティングの形態などさまざまな利用方法についての実証研究が行われている.生命科学・医学系の研究者にとってはクラウド的な利用の方法も利用の需要も高いと思われるので,興味のある方はプロジェクトのホームページなどを参照されたい10).
一方,わが国ではヒトゲノムプロジェクト以来,大規模ゲノム解析に特化したスパコンとして東京大学医科学研究所(医科研)のSHIROKANEや国立遺伝学研究所の遺伝研スパコンがある.遺伝研スパコンは現在第一義的には国際塩基配列データベースの構築・運用のためのスパコンであるが,医科研のSHIROKANEと同様,一般の研究者への計算リソースの提供も行っている.本特集ではスパコンの具体的な使い方の入門として遺伝研スパコンの使い方について紹介する(小笠原・丹生の稿).遺伝研スパコンはビッグデータ解析向けに特化したクラスタ計算機であり,小笠原・丹生の稿で紹介したクラスタ計算機特有の操作方法を理解すれば他のスパコンやクラウドを用いた解析の際にも役に立つ.一方,遺伝研スパコンや東大医科研SHIROKANEだけでは急増する計算需要のすべてに対応出来ず,もっと大きな枠組みが必要である.
ゲノム医療などの推進に伴い患者や医療研究参加者等の機微(センシティブ)情報を含む大規模データの共有方法が国際的な課題となるなか,日本でも内閣官房に設置された健康・医療戦略室,および国立研究開発法人日本医療研究開発機構(AMED)を中心にゲノム医療研究支援事業が行われている11).事業を支える計算インフラ的な部分についてはAMEDゲノム制限共有データベース(AGD)および電算資源(スーパーコンピューター)の共用サービスが提供されており,現在のところ,前者のAGDは遺伝研DDBJセンターと国立研究開発法人科学技術振興機構傘下のバイオサイエンスデータベースセンター(National Bioscience Database Center,NBDC)が共同で構築しており,後者の電算資源は東北大学東北メディカル・メガバンク機構がスパコン上でdata-visitingモデル利用環境の実装と運用を行っている.さらに今後のデータ量の増大に対応するため,より大きな枠組みでの対応が議論されており,技術的な検討を進めるために現在東北メディカル・メガバンク機構,国立遺伝学研究所(DDBJ),東京大学医科学研究所ヒトゲノム解析研究センター(HGC),国立がん研究センター(NCC),国立国際医療研究センター(NCGM)が共同で実証実験も含めた環境構築を進めている(木下・岡村の稿).
2クラウドの活用方法
生命科学・医学系の大規模データ解析は,専門機関だけの話ではなく単独のラボでも行われるようになっている.急増する計算需要に対応するもう一つの方法はAmazon Web Service (AWS),Goolge Cloud Platform(GCP),Microsoft Azure等に代表される商用クラウドの利用である.商用クラウドはもともと電力事業のアナロジーであり12),このような基幹インフラを海外の企業に依存することの危険性について懸念される部分もあるが13),これについては政策の専門家の議論を待つことにして,こと目下の生命科学・医学研究をスピード感をもって進めるには商用クラウドの利用は必然と言える.ベンダーロックインによるコスト面などの心配もあるが,これについてはクラウドベンダーを複数に分散するマルチクラウド構成による対応が研究開発されている.
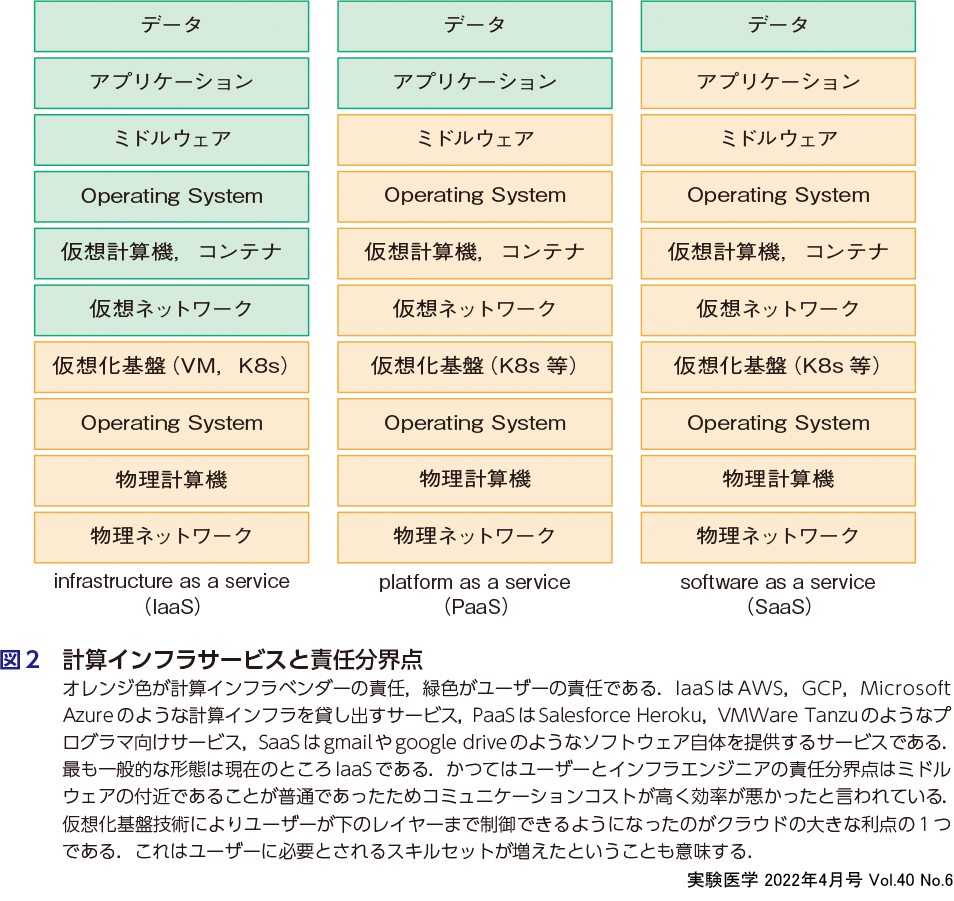
医療データを扱うためには,各種のセキュリティーガイドラインに従う必要があり,これらを満たす計算機リソースを各ラボで準備することは簡単ではない.商用クラウドではさまざまなセキュリティー規格等の認証を取得している場合が多く,計算インフラを準備するうえでよい出発点となる.ただしクラウド上で行われるすべての活動についてクラウドベンダーの責任となるわけではなく,利用しているサービスの責任分界点がどこにあるのか理解しておくことが重要である(図2).日本では3省2ガイドラインとよばれる「医療情報システムの安全管理に関するガイドライン」「医療情報を取り扱う情報システム・サービスの提供事業者における安全管理ガイドライン」で医療系で必要なセキュリティーガイドラインが定められており,責任分界点の考え方やリスク管理の方法も記載されている.
実際にクラウドを利用する段になると,クラウド業者のサービスレベルの情報を集めることは簡単ではなく,どのクラウド業者を利用したらよいか判断が難しい.この問題を解決するための1つの方法は,第三者がクラウド業者を同一の基準で評価することであるが,このような例として情報処理推進機構(IPA)の「政府情報システムのためのセキュリティ評価制度(ISMAP)」や国立情報学研究所の学認クラウド導入支援サービスがある.後者においてはクラウド業者に聞き取りを行い,相互に比較可能なサービスレベルチェックシートを作成している(合田の稿).
3ネットワークの整備
大規模データを自前の計算機にダウンロードするにしろスパコン,クラウドなどで利用するにしろ,高速ネットワークが利用できることが大前提となる.医療系の現場の計算機・ネットワーク環境は筆者の見る限り多種多様の状況であるようだ.病院の外までは高速なネットワークが来ているが病院内の回線が細いままであるとか,日中にゲノムデータをスパコンに転送すると病院に迷惑がかかるので夜間だけ転送するプログラムを書いて何日もかけて転送するといった話も聞く.しかし本来,日本の大学や研究機関等では国立情報学研究所が構築している学術情報ネットワーク(SINET)のおかげで国際的に見てもかなり高水準の高速なネットワーク環境が享受できる.SINETは2022年度から幹線400 GbpsのSINET6の運用が開始される.この基幹ネットワークを各大学は無料で利用可能である.基幹ネットワークの各所に設置された接続拠点(DC)から各大学への引き込み線を契約することでSINETが利用可能となる.この引き込み線は各大学の料金負担となるが,SINETを利用せず全体を商用線で構築する場合に比べたら遙かに安価に高速ネットワークを利用できる.またクラウドベンダーに対する専用線をSINET経由で構築することによりクラウドのネットワーク使用料金の大幅な割引を得ることもできる.
4スパコン,クラウドを用いた大規模解析
本特集ではさらにスパコン,クラウドを用いた大規模ゲノム解析の実例として,がん,遺伝性疾患,新型コロナウイルスの話題について紹介する.
がん研究についてはAMEDの革新的がん医療実用化研究事業における,約3,000人の遺伝性腫瘍疑いの患者の全ゲノム解析が行われた.本解析を行うにあたり国立がん研究センターでは商用クラウド(AWS)を利用することにより,各種セキュリティーガイドラインに準拠しつつ解析に必要なインフラを短期間で構築することができた(白石らの稿).
遺伝性疾患の研究の例として,将来のがんや難病のゲノム研究のコントロールデータ取得のためのナショナルセンターバイオバンクネットワーク(NCBN)のバイオバンク9,850人の全ゲノム解析の実践例を紹介する.なお,ここで解析された30×全ゲノム(WGS)データの解析はCPUのみで実行するGATKの公式実装を使うと30時間程度かかるが,GPGPUを用いた商用実装であるNVIDIA Parabricksを用いると,遺伝研スパコンでは90分ほどで解析が終了する.最新のGPUをフル搭載するとさらに半分以下に時間が短縮できるという報告もある.これほど高速な処理を行うためにはディスクI/O(外部記憶装置への読み書き速度)が律速にならないよう計算機の設計をしておく等の考慮は必要である(河合の稿).
また,2022年現在も世界で猛威をふるう新型コロナウイルス(SARS-CoV-2)のゲノム解析については,国立遺伝学研究所においてもその全ゲノム解析による分子疫学調査(SARS- CoV-2 RNA全ゲノム解析)を静岡県と連携・協働して進めており14),関連する研究状況の紹介および研究を支えるデータ共有機構としてのGISAID(Global Initiative on Sharing Avian Influenza Data)および国際塩基配列データベースの役割や課題について紹介した(中川の稿).
おわりに
広汎かつ発展途上の話題となるため,本特集ではスパコンやクラウドを使いはじめるための準備に関する話題と応用の現場に関する話題が中心となり,バイオインフォマティクスや機械学習アルゴリズムなどの具体的な内容やツールの具体的な利用方法については扱いきれず,概説は生命科学・医学系の研究者の方々には必ずしも馴染み深いとは言えないような情報技術の話題が多くなってしまったが,大規模データの共有と解析のための環境構築と利用方法の習得はこれからますます必須の技術となっていく.医療系の大規模データ解析をこれからはじめようという方々に現場で実際に環境を構築する際の雰囲気が伝われば幸いである.
文献
- 「Genomics in the Cloud: Using Docker, GATK, and WDL in Terra」(Van der Auwera GA & O’Connor BD),O’Reilly Media(2020)
- Southan C & Cameron G:Beyond the tsunami: developing the infrastructure to deal with life sciences data.「The Fourth Paradigm: Data-Intensive Scientific Discovery」(Hey T, et al, eds),Microsoft Research(2009)
- Cook CE, et al:Nucleic Acids Res, 48:D17-D23, doi:10.1093/nar/gkz1033(2020)
- Ogasawara O, et al:Nucleic Acids Res, 41:D25-D29, doi:10.1093/nar/gks1152(2013)
- Knoppers BM & Joly Y:Hum Genet, 137:569-574, doi:10.1007/s00439-018-1923-y(2018)
- Birney E, et al:BioRxiv, doi.org/10.1101/203554(2017)
- 「スーパーコンピュータ『富岳』TOP500、HPCG、HPL-AI、Graph500にて4期連続世界第1位を獲得(2021年11月16日)」
- 「スーパーコンピュータ『富岳』TOP500、HPCG、HPL-AIにおいて3期連続の世界第1位を獲得(2021年6月28日)」
- 「スーパーコンピュータ『富岳』記者説明会」
- 「富岳クラウドプラットフォーム」
- 「ゲノム医療推進支援」
- 「Does It Matter?: Information Technology and the Corrosion of Competitive Advantage」(Carr NG), Harbard Business School Press(2004)/翻訳版「ITにお金を使うのは、もうおやめなさい」(清川幸美, 訳),ランダムハウス講談社(2005)
- 「Merkel Calls Trump Ban from Twitter, Other Media Platforms ‘Problematic’(VOA News, January 11, 2021)」
- 「国立遺伝学研究所が取り組む新型コロナウイルス・全ゲノム解析の紹介」
本記事のDOI:10.18958/6987-00001-0000089-00
著者プロフィール
小笠原 理:1992年東京大学理学部生物学科動物学コース卒業.’98年東京大学大学院理学系研究科生物科学専攻博士課程単位取得退学.博士(理学).国立遺伝学研究所特任准教授,システム管理部門長.国立情報学研究所特任准教授.集団遺伝学,データベース,スーパーコンピューター,マルチクラウド技術の研究開発.先天性疾患の実兄をもつ身として難病研究などに貢献できれば幸いである.